
팀 프로젝트를 진행하면서 정리해둔다고 해뒀었는데, 내가 중점적으로 분석했던 부분만 일단 정리해 보았다. 맡았던 부분은 주로 전처리 단계에서 데이터 필드(컬럼, 변수)별 이상치 처리였다.
데이터 개요 및 문제 정의
데이터를 받을 수 있는 곳
https://archive.ics.uci.edu/ml/datasets/Online+Shoppers+Purchasing+Intention+Dataset
UCI Machine Learning Repository: Online Shoppers Purchasing Intention Dataset Data Set
Online Shoppers Purchasing Intention Dataset Data Set Download: Data Folder, Data Set Description Abstract: Of the 12,330 sessions in the dataset, 84.5% (10,422) were negative class samples that did not end with shopping, and the rest (1908) were positive
archive.ics.uci.edu
데이터 개요
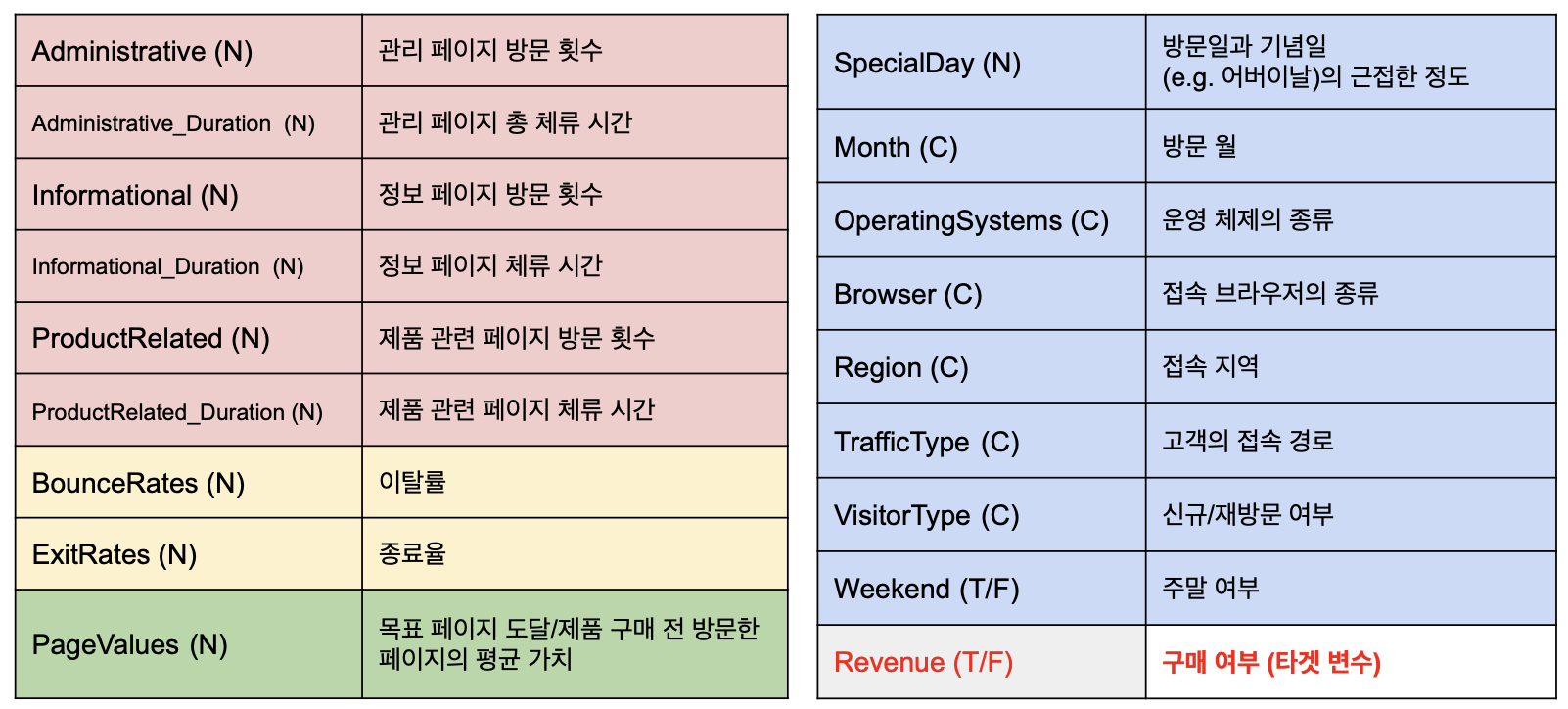
필드별 색상은 분석의 편의를 위해 성격이 비슷한 것끼리 임의로 구분한 것이며,
괄호안 문자의 의미는 다음과 같다.
N : Numerical Feature(숫자형 변수)
C : Categorical Feature(범주형 변수)
T/F : True of False(참, 거짓)
문제 정의 : 고객 데이터를 통해 구매 행위('Revenue'-구매 여부)를 예측
데이터 분석 전 사전 작업
라이브러리 불러오기
# 전처리
import numpy as np
import pandas as pd
# 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
import plotly.figure_factory as ff
from plotly.offline import iplot
from plotly.subplots import make_subplots
%matplotlib inline
# warning 메시지 무시하기
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
데이터 불러오기
df = pd.read_csv('/Users/moriaty/Desktop/IBA/토이 프로젝트 1(22.3.20~)/online_shoppers_intention.csv')
# 데이터 파악
df.head(10)
# 변수 및 결측치 파악
df.info()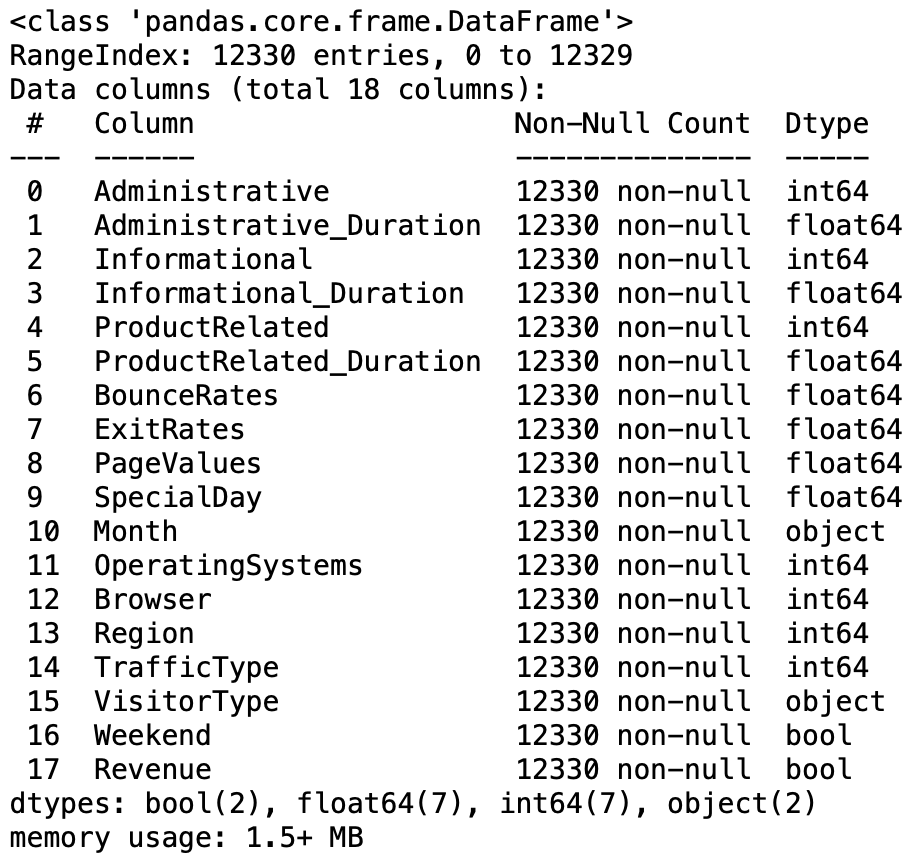
결측치는 없는 것으로 확인되었다.
필드별 이상치 탐색
(1) '~_Duration' 이름을 가진 필드들
Administrative_Duration : 관리 페이지 체류 시간
Informational_Duration : 정보 페이지 체류 시간
ProductRelated_Duration : 제품 관련 페이지 체류 시간
# kdeplot : 분포를 보기 쉽게 나타내주는 그래프
fig, (axis1,axis2, axis3) = plt.subplots(3,1,figsize=(15,5))
sns.kdeplot(df['Administrative_Duration'], ax=axis1 )
sns.kdeplot(df['Informational_Duration'], color="orange" , ax=axis2)
sns.kdeplot(df['ProductRelated_Duration'], color="green" , ax=axis3)
plt.show()
세 필드의 분포를 볼 때, 이상치로 보이는 값들이 존재한다. 그러나 이와 같은 값들이 진짜 이상치인지, 그리고 그것들을 어떻게 처리할 것인지는 간단하게 판단할 수 없다.
그래서 내가 생각해낸 방법은 분석의 목적이 구매자의 행위를 예측하는 것이고 그 값이 참, 거짓으로 이루어져 있기 때문에 이상치를 제거하고도 원본 데이터의 참, 거짓 값의 비율에 큰 변화를 가져오는지 알아보는 것이었다.
만약 원본 데이터의 참, 거짓 값의 비율에 큰 변화를 가져온다면 이후 정제된 데이터로 학습시킬 때 모델의 성능에 부정적인 영향을 미칠 것으로 생각되었기 때문이다. 즉, 그렇게 된다면 제거한 이상치가 이상치가 아니라 원본 데이터 속에서 어떠한 의미를 가지기 때문에 제거되서는 안된다고 생각했다.
이상치 제거
# 이상치 파악 함수 생성
def get_outlier(df=None, column=None, weight=1.5):
quantile_25 = np.percentile(df[column].values, 25)
quantile_75 = np.percentile(df[column].values, 75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
outlier_index = df[column][(df[column] < lowest_val) | (df[column] > highest_val)].index
return outlier_indexoutlier_AD = get_outlier(df=df, column="Administrative_Duration", weight=1.5)
outlier_ID = get_outlier(df=df, column="Informational_Duration", weight=1.5)
outlier_PD = get_outlier(df=df, column="ProductRelated_Duration", weight=1.5)
# 이상치로 판단한 데이터의 index들을 저장
outlier_1 = outlier_AD | outlier_ID | outlier_PDdf_1 = df.drop(df.index[outlier_1], inplace=False) # inplace=False 로 해야 새로운 데이터 프레임에 저장됨
이상치를 제거한 새로운 데이터프레임 'df_1'을 생성했다.
# 'df_1'에서의 Target value("Revenue") 분포
f, ax = plt.subplots(1, 2, figsize=(10, 5))
df_1['Revenue'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie plot - Revenue')
ax[0].set_ylabel('')
sns.countplot('Revenue', data=df_1, ax=ax[1])
ax[1].set_title('Count plot - Revenue')
plt.show()
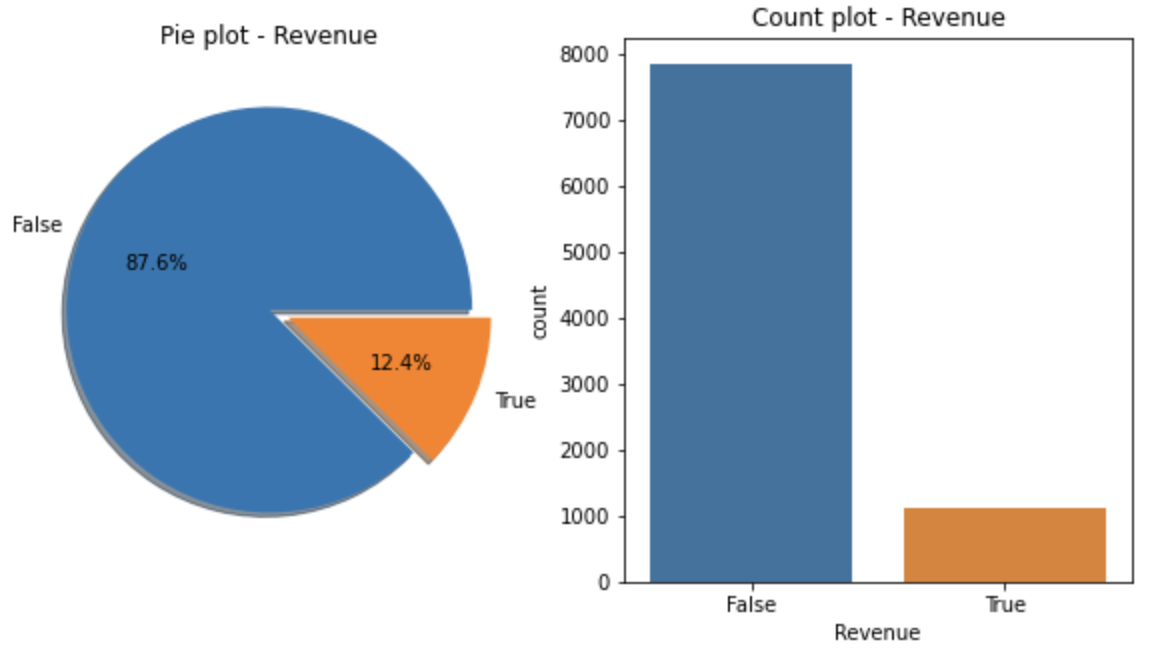
이상치를 제거한 결과, "Revenue"가 'True'인 값의 비율이 15.5%에서 12.4%로 원본 데이터 대비 3.1%p 감소했다. 이는 기존 데이터 프레임 대비 20%가 줄어든 수치로서, 세 개의 변수("Administrative Duration", "Informational Duration", "Product Related Duration")의 이상치를 전부 제거(3,376개)하는 것이 예측 모델을 만드는 데에 손실을 가져다줄 것으로 판단된다.
이처럼 판단한 이유는 다음과 같다. 세 가지의 변수는 한 번의 세션 동안 카테고리별 사이트에 머무는 시간과 관련된 변수이기 때문에 '그 값이 증가하면 상품의 구매로 이어질 수 있다("Revenue"='True')'라는 가설을 생각해 보았고, 통계적으로 이상치라 판단이 된다고 하더라도 그 값이 Target value를 예측하는 데에 유의미한 영향을 끼친다면 이상치로 판단하지 않는 것이 적절하다고 생각했다.
실제로 이상치를 제거한 후, Target value의 비율이 크게 변한 것으로 보아 이상치를 전부 제거했을 때 얻는 손실이 이익보다 더 많을 것이라고 판단했다. 그러나 20%라는 수치를 절대적으로 평가하기 어려운 것도 사실이다.
최종으로, (1) '~_Duration'에서는 제거할 이상치가 없다고 판단했다.
(2) 'BounceRates' & 'ExitRates'
사실 이 데이터를 다루면서 가장 어려웠던 부분은 바로 해당 변수들에 대한 이해였다. 어떠한 기준으로 수집된 데이터인지 명확하게 알 수가 없어서 관련 정보를 담고 있는 사이트들을 종합해 변수의 의미를 나름대로 정리해보았다.
'BounceRates(이탈률)' : 이탈률, 한 페이지만 보고 그 페이지에서 바로 나가는 비율, 이탈 수 / 페이지 세션 X 100% 여기서 말하는 이탈은 페이지에서 고객이 아무런 상호작용을 거치지 않고 떠난 경우를 의미. 예를 들어 클릭, 스크롤 다운, 스와이프 등
→ 한 세션 동안 사이트 내에서 페이지들을 클릭해 이동하면서 아무런 상호작용을 하지 않은 비율
'ExitRates(종료율)' : 종료율, 한 페이지에서 세션이 종료된 비율, 페이지 종료 수 / 페이지 뷰 수 X 100(%).
→ 종료란, 해당 페이지가 탐색 페이지의 마지막에 해당하는 페이지 뷰 수를 의미
# kdeplot
fig, (axis1,axis2, axis3) = plt.subplots(3,1,figsize=(15,10))
sns.kdeplot(df['BounceRates'], ax=axis1 )
sns.kdeplot(df['ExitRates'], color="orange" , ax=axis2)
sns.kdeplot(df['PageValues'], color="green" , ax=axis3)
* 'PageValues'는 이후에 분석
'~_Duration'의 이름을 가진 필드들의 분포와는 다르게 특정한 값(0.20)에서 이상치를 보이는 것을 확인할 수 있다. 이상치를 갖는 데이터들을 분석해보았다.
'cond_1', 'cond_2' 조건 2개를 모두 만족하는 데이터들을 인덱싱
cond_1 = df['BounceRates'] == 0.2 # 700rows
cond_2 = df['ExitRates'] == 0.2 # 710rows
df[cond_1 & cond_2] # 따라서, "BounceRates"가 '0.2'인 모든 데이터는 "ExitRates"또한 '0.2'이다.
df['BounceRates'] == 0.2 : 700rows * 미리 확인함
df['ExitRates'] == 0.2 : 710rows * 미리 확인함
따라서, "BounceRates"가 '0.2'인 모든 데이터는 "ExitRates"또한 '0.2'임을 알 수 있다.
이에 기반해 "ExitRates"가 '0.2'인 데이터들의 특성을 새로운 데이터 프레임('df_outlier1')을 생성해 살펴보기로 한다.
# "ExitRates"가 '0.2'인 데이터들의 특성을 분석하기 위해 새로운 데이터 프레임('df_outlier1')을 생성
df_outlier1 = df[df['ExitRates'] == 0.2]# 새롭게 생성한 'df_outlier1'에서의 Target value 분포 확인
f, ax = plt.subplots(1, 2, figsize=(10, 5))
df_outlier1['Revenue'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie plot - Revenue')
ax[0].set_ylabel('')
sns.countplot('Revenue', data=df_outlier1, ax=ax[1])
ax[1].set_title('Count plot - Revenue')
plt.show()

전체 데이터의 99.6%가 Target value값을 'False'로 가진다.
"ExitRates"(혹은 "BounceRates")가 0.2의 값을 가지면 거의 대부분 구매 행위로 이어지지 않는다고 판단할 수 있다. 이는 종료율과 이탈률의 정의를 생각해 볼 때 직관적으로 할 수 있는 판단과 결을 같이한다.
# 새롭게 생성한 'df_outlier'에서의 '~_Duration'필드 분석
fig, (axis1,axis2, axis3) = plt.subplots(3,1,figsize=(15,5))
sns.boxplot(df_outlier1['Administrative_Duration'], ax=axis1 )
sns.boxplot(df_outlier1['Informational_Duration'], color="orange" , ax=axis2)
sns.boxplot(df_outlier1['ProductRelated_Duration'], color="green" , ax=axis3)
plt.show()
'ExitRates'(혹은 'BounceRates')가 0.2의 값을 가지면 각 카테고리별 페이지의 탐색 시간은 모두 '0'임을 확인. 이탈률과 종료율이 모두 0.20라는 값을 가지는 데 어떠한 페이지도 방문하지 않았다는 것은 논리적으로 설명되지 않는다.
정리해보면,
'ExitRates', 'BounceRates' 필드에서는 분포가 특이한 상황을 연출된다는 점과, 타 필드('Revenue', '~_Duration')와의 관계를 고려해봤을 때 이 데이터들은 온라인 구매 사이트에서 일어난 '비정상적인 접속 형태'와 같은 이상치라고 판단했다.
최종으로, (2) 'ExitRates', 'BounceRates' 에서는 두 필드에서 모두 0.20의 값을 가지는 데이터 700개를 이상치로 판단했다.
(3) 'PageValues'
'PageValues' : 목표 페이지 도달, 제품 구매 전 방문한 페이지의 평균 가치
'ExitRates', 'BounceRates'와 마찬가지로 자체 의미를 해석하는 데에 어려움이 있었다. 구매 행위가 일어날 수 있는 페이지 그리고 구매 행위가 일어나기 이전에 방문한 페이지를 임의의 값으로 측정해 정량화한 값으로 해석했다. 직관적으로 이해해보면, 'PageValues'의 값이 커야 구매 행위가 일어날('Revenue' == True) 가능성이 크다고 이해할 수 있다.
그래서 먼저 타겟 벨류에 해당하는 'Revenue'가 True(구매 행위가 일어남)인지, False(구매 행위가 일어나지 않음)인지에 따라 데이터프레임을 쪼갠 뒤 'PageValues'의 분포를 확인하기로 결정했다.
# Target value에 따른 "PageValues"의 분포 확인
df_true = df[df["Revenue"] == True] # Target Value가 'True'인 데이터 프레임 생성
df_false = df[df["Revenue"] == False] # Target Value가 'False'인 데이터 프레임 생성
fig, (axis1,axis2) = plt.subplots(2,1,figsize=(18,8))
sns.boxplot(df_true['PageValues'], color="purple", ax=axis1 )
sns.boxplot(df_false['PageValues'], color="orange" , ax=axis2)
plt.show()
예상대로 구매행위가 일어난 데이터에 'PageValues'의 값이 양의 값을 가지는 데이터가 대부분 분포해 있었다. 그러나, 여기서 특이한 점을 발견할 수 있었는데,

기술해둔바와 같이 'PageValues'의 값이 0인데도 구매행위가 일어난 데이터들이 존재했다는 점이다.(빨간색 원으로 표시된 부분) 이는 필드에 대해 이해한 바와 모순되는 현상이라고 볼 수 있다. 구매 행위가 일어났다면, 목표 페이지에 분명히 도달했을 것이고 그 이전에 거친 페이지들 역시 존재해야할 텐데 그 값이 0인 상태로 구매 행위가 일어났다고는 이해할 수 없기 때문이다.
최종으로, (3) 'PageValues'에서는 값이 0인데도 구매 행위가 일어난('Revenue'==True) 데이터 370개를 이상치로 판단했다.
(2), (3)에 따른 이상치 제거
outlier_idx1 = df[df['ExitRates'] == 0.2].index # (2) 이상치들의 데이터 프레임 인덱스
outlier_idx2 = df[(df['Revenue'] == True) & (df['PageValues']==0)].index # (3) 이상치들의 데이터 프레임 인덱스
df_1 = df.drop(outlier_idx1 | outlier_idx2, inplace=False)
df_1
후기
데이터프레임에 존재하는 이상치를 제거하기 위해서는 명확한 근거가 필요하다. 이번 프로젝트를 거치면서 그 부분을 신경을 쓰고자 노력했는데 조금 부족했던 것 같다. 나름의 사고방식으로 논리는 만들어냈지만, 역시나 제대로 된 도메인 지식이 없다 보니 한계를 마주했던 것 같다. 해당 데이터프레임의 필드들 '이탈률', '종료율' 그리고 '페이지값'과 같은 것들에 대한 정확한 지식이 있었다면 이상치를 판단하고 제거하는 데에 있어 더 확신을 가질 수 있었을 테니 말이다.
'도메인 지식'이 항상 걸림돌이자 중요한 변수가 된다는 것을 느낀다. 다양한 영역에서 얻는 데이터들을 분석할 때마다 해당 영역의 도메인 지식이 부족하다면 분석을 시작조차 할 수가 없다. 하지만 더 어려운 것은 그 도메인 지식을 얼마만큼의 깊이로 알고 있어야 하는지도 영역마다 다르다는 것이다. 데이터 분석을 한다고는 하지만 내가 여기서 얼마나 전문성을 가질 수 있게 될지는 더 많은 것들에 달려있다.
'데이터 분석 프로젝트' 카테고리의 다른 글
| Kaggle(캐글) 타이타닉 데이터 분석 - 결측치 처리 및 변수간 관계에 대한 고민 (0) | 2022.08.07 |
|---|